指标聚合
此类聚合基于从要聚合的文档中以一种或另一种方式提取的值来计算指标。这些值通常从文档的字段中提取(使用字段数据),但是也可以使用脚本生成。
数值指标聚合是一种特殊类型的指标聚合,可输出数值。一些聚合输出单个数值度量(例如avg)并被称为single-value numeric metrics aggregation,其他聚合则生成多个度量(例如stats)并被称为multi-value numeric metrics aggregation。当这些值充当某些存储桶聚合的直接子聚合(某些存储桶聚合使您可以基于每个存储桶中的数字度量对返回的存储桶进行排序)时,单值和多值数字度量聚合之间的区别将发挥作用。
平均值
一种单值度量聚合,用于计算从聚合文档中提取的数值的平均值。这些值可以从文档中的特定数字字段中提取,也可以由提供的脚本生成。
假设数据由代表学生考试成绩(介于0到100之间)的文档组成,我们可以使用以下方法取平均分数:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}以上汇总计算了所有文档的平均成绩。聚合类型为avg,该field设置定义将在其上计算平均值的文档的数字字段。上面将返回以下内容:
{
...
"aggregations": {
"avg_grade": {
"value": 75.0
}
}
}聚合的名称(avg_grade上面)还用作键,通过该键可以从返回的响应中检索聚合结果。
脚本
根据脚本计算平均成绩:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"source" : "doc.grade.value"
}
}
}
}
}这会将script参数解释为inline具有painless脚本语言且没有脚本参数的脚本。要使用存储的脚本,请使用以下语法:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}值脚本
事实证明,该考试远远超出了学生的水平,因此需要进行成绩更正。我们可以使用值脚本来获取新的平均值:
POST /exams/_search?size=0
{
"aggs" : {
"avg_corrected_grade" : {
"avg" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}缺少值
该missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /exams/_search?size=0
{
"aggs" : {
"grade_avg" : {
"avg" : {
"field" : "grade",
"missing": 10
}
}
}
}grade字段中没有值的文档将与具有该值的文档归入同一存储桶10。
加权平均聚合
一个single-value度量聚集,计算数字值的加权平均值被从聚合文档中提取。这些值可以从文档中的特定数字字段中提取。
在计算常规平均值时,每个数据点都具有相等的"权重''...它对最终值的贡献均等。另一方面,加权平均对每个数据点的加权不同。每个数据点对最终值的贡献量是从文档中提取的,或由脚本提供的。
作为公式,加权平均值为 ∑(value * weight) / ∑(weight)
可以将规则平均值视为每个值的隐式权重为的加权平均值1。
表3. weighted_avg参数
参数名称
描述
需要
默认值
value
提供值的字段或脚本的配置
需要
weight
提供权重的字段或脚本的配置
需要
format
数字响应格式化程序
可选的
value_type
有关纯脚本或未映射字段的值的提示
可选的
在value和weight对象有每场具体配置:
表4. value参数
参数名称
描述
需要
默认值
field
应当从中提取值的字段
需要
missing
如果字段完全丢失,则使用的值
可选的
表5. weight参数
参数名称
描述
需要
默认值
field
应从中提取权重的字段
需要
missing
如果字段完全丢失,则使用的权重
可选的
例子
如果我们的文档有一个"grade"包含0-100数值分数的"weight"字段和一个包含任意数值权重的字段,我们可以使用以下方法计算加权平均值:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}产生如下响应:
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}虽然每个字段允许多个值,但仅允许一个权重。如果聚合遇到的文档具有多个权重(例如,weight字段是多值字段),它将引发异常。如果遇到这种情况,则需要script为权重字段指定a ,然后使用脚本将多个值组合成一个要使用的值。
该单个权重将独立应用于从value字段中提取的每个值。
此示例说明如何使用单个权重对具有多个值的单个文档进行平均:
POST /exams/_doc?refresh
{
"grade": [1, 2, 3],
"weight": 2
}
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}这三个值(1,2和3)将作为独立值包括在内,其权重为2:
{
...
"aggregations": {
"weighted_grade": {
"value": 2.0
}
}
}聚合返回2.0结果,这与我们手工计算时所期望的相匹配: ((1*2) + (2*2) + (3*2)) / (2+2+2) == 2
脚本
值和权重都可以从脚本而不是字段中派生。作为一个简单的示例,以下内容将使用脚本在文档的等级和权重中添加一个:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"script": "doc.grade.value + 1"
},
"weight": {
"script": "doc.weight.value + 1"
}
}
}
}
}缺失值
该missing参数定义应如何处理缺少值的文档。默认行为是不同的value和weight:
默认情况下,如果value缺少该字段,则忽略该文档,并将聚合移至下一个文档。如果weight缺少该字段,则假定其权重为1(类似于正常平均值)。
可以使用以下missing参数覆盖这两个默认值:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade",
"missing": 2
},
"weight": {
"field": "weight",
"missing": 3
}
}
}
}
}基数聚合
一个single-value度量聚集,计算不同的值的近似计数。值可以从文档中的特定字段中提取,也可以由脚本生成。
假设您正在为商店的销售建立索引,并希望计算与查询匹配的已售产品的唯一数量:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}响应:
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}精密控制
此聚合还支持以下precision_threshold选项:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type",
"precision_threshold": 100
}
}
}
}这些
precision_threshold选项允许以内存换取准确性,并定义一个唯一的计数,在该计数以下,期望计数接近准确。超过此值,计数可能会变得更加模糊。支持的最大值是40000,高于此阈值的阈值将与阈值40000产生相同的效果。默认值为3000。
计数是近似值
计算精确计数需要将值加载到哈希集中并返回其大小。当处理高基数集和/或较大的值时,这不会扩展,因为所需的内存使用情况以及在节点之间传递这些每个分片集的需求会占用过多的群集资源。
此cardinality聚合基于 HyperLogLog ++ 算法,该算法基于具有一些有趣属性的值的哈希值进行计数:
可配置的精度,该精度决定了如何以内存换取精度,
低基数集的精度很高,
固定的内存使用量:无论是否有成百上千的唯一值,内存使用量仅取决于配置的精度。
对于的精确阈值c,我们正在使用的实现大约需要c * 8字节。
下表显示了阈值前后误差如何变化:
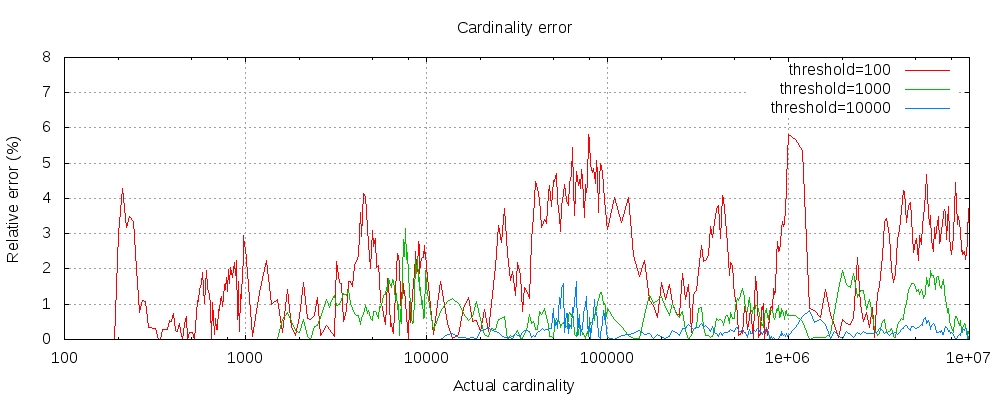
对于所有三个阈值,计数均已精确到配置的阈值。尽管不能保证,但情况可能如此。实践中的准确性取决于所讨论的数据集。通常,大多数数据集始终显示出良好的准确性。还要注意,即使阈值低至100,即使计数数百万个项目,误差仍然非常低(如上图所示为1-6%)。
HyperLogLog ++算法取决于散列值的前导零,数据集中散列的确切分布会影响基数的准确性。
还请注意,即使阈值低至100,即使计数数百万个项目,误差仍然非常低。
预先计算的哈希
在具有高基数的字符串字段上,将字段值的哈希存储在索引中然后在此字段上运行基数聚合可能会更快。这可以通过从客户端提供哈希值来完成,也可以让Elasticsearch使用mapper-murmur3插件为您计算哈希值来完成 。
预计算哈希通常仅在非常大和/或高基数的字段上有用,因为它可以节省CPU和内存。但是,在数字字段上,哈希运算非常快,存储原始值所需的内存与存储哈希值所需的内存相同或更少。对于低基数的字符串字段也是如此,特别是考虑到这些字段进行了优化以确保每个段的每个唯一值最多计算一次哈希。
脚本
该cardinality指标支持脚本编写,但是由于需要实时计算哈希值,因此性能受到明显影响。
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script": {
"lang": "painless",
"source": "doc['type'].value + ' ' + doc['promoted'].value"
}
}
}
}
}这会将script参数解释为inline具有painless脚本语言且没有脚本参数的脚本。要使用存储的脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script" : {
"id": "my_script",
"params": {
"type_field": "type",
"promoted_field": "promoted"
}
}
}
}
}
}值缺失
该missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search?size=0
{
"aggs" : {
"tag_cardinality" : {
"cardinality" : {
"field" : "tag",
"missing": "N/A"
}
}
}
}
tag字段中没有值的文档将与具有该值的文档归入同一存储桶N/A。
扩展统计汇总
一个multi-value指标聚集了从聚集的文档中提取的数值,计算统计。这些值可以从文档中的特定数字字段中提取,也可以由提供的脚本生成。
所述extended_stats聚合是的扩展版本stats聚集,其中附加的度量被加到如sum_of_squares,variance,std_deviation和std_deviation_bounds。
假设数据由代表学生考试成绩(0至100)的文档组成
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : { "extended_stats" : { "field" : "grade" } }
}
}上面的汇总计算了所有文档的成绩统计。聚合类型为,extended_stats并且该field设置定义将要计算统计信息的文档的数字字段。上面将返回以下内容:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"std_deviation": 25.0,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0
}
}
}
}聚合的名称(grades_stats上面)还用作键,通过该键可以从返回的响应中检索聚合结果。
标准偏差范围
默认情况下,该extended_stats指标将返回一个名为的对象std_deviation_bounds,该对象提供一个与平均值相差正负两个标准差的间隔。这是可视化数据差异的有用方法。如果要使用其他边界,例如三个标准偏差,则可以sigma在请求中进行设置:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"sigma" : 3
}
}
}
}
sigma控制应显示多少平均值的标准偏差
sigma可以是任何非负双精度值,这意味着您可以请求非整数值,例如1.5。值0有效,但只会返回边界upper和lower边界的平均值。
标准偏差和界限需要正态性
默认情况下会显示标准差及其界限,但是它们并不总是适用于所有数据集。您的数据必须正态分布以使指标有意义。标准差背后的统计数据假设数据呈正态分布,因此,如果您的数据偏左或偏右,则返回的值将产生误导。
脚本
根据脚本计算成绩统计信息:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"script" : {
"source" : "doc['grade'].value",
"lang" : "painless"
}
}
}
}
}这会将script参数解释为inline具有painless脚本语言且没有脚本参数的脚本。要使用存储的脚本,请使用以下语法:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}值脚本
事实证明,该考试远远超出了学生的水平,因此需要进行成绩更正。我们可以使用值脚本来获取新的统计信息:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"script" : {
"lang" : "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}值缺失
该missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"missing": 0
}
}
}
}
grade字段中没有值的文档将与具有该值的文档归入同一存储桶0。
Last updated
Was this helpful?